



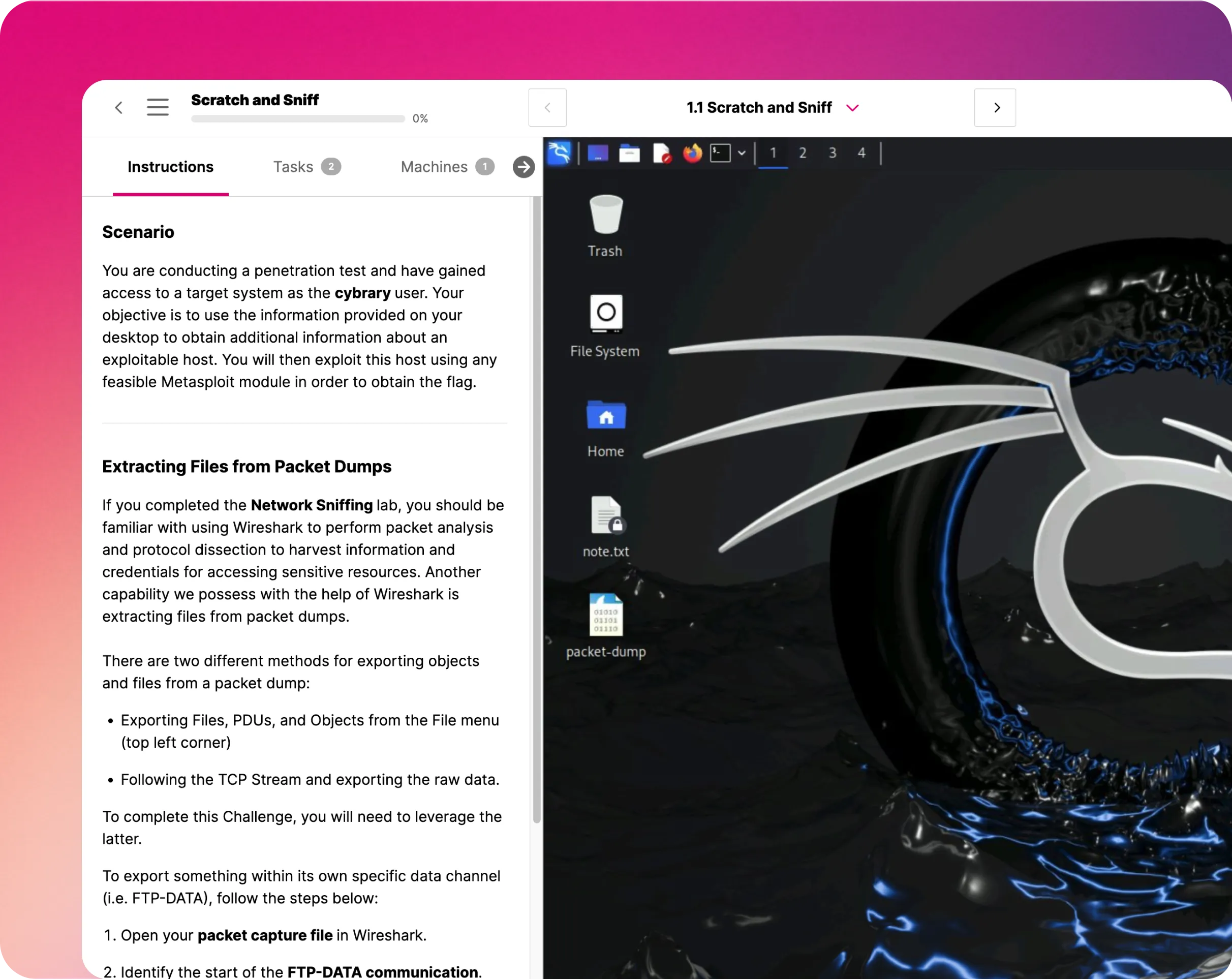









Python Basics
In this hands-on lab, you will learn the basics of Python. You will practice using several key Python concepts using the REPL interactive shell, as well as develop a simple script using VS Code.

1
H
30
M
Time
beginner
difficulty
1
ceu/cpe
Course Content
Course Description
Upon completing this lab, you will be able to:
- Describe key features of the Python programming language.
- Identify practical applications of Python.
- Manipulate basic Python syntax in the Python interactive shell.
- Use Python to create a basic script.
Provider
Certificate of Completion




